0 写在前面
有段时间没有更新博客了,这篇其实是今年9月自己在一次组会上展示的内容,自我感觉做的还可以,因此与大家分享一下。本文中的一些见解可能不够严谨,对于理解不对的地方请不吝赐教。
1 当我们谈优化时,我们谈些什么
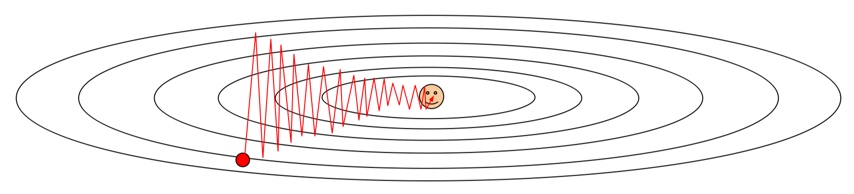
提到优化,我的脑海里最先想起的,便是Stanford CS231n的Slides中那张经典的下山图:

优化问题可以看做是我们站在山上的某个位置(当前的参数信息),想要以最佳的路线去到山下(最优点)。首先,直观的方法就是环顾四周,找到下山最快的方向走一步,然后再次环顾四周,找到最快的方向,直到下山——这样的方法便是朴素的梯度下降——当前的海拔是我们的目标函数值,而我们在每一步找到的方向便是函数梯度的反方向(梯度是函数上升最快的方向,所以梯度的反方向就是函数下降最快的方向)。
事实上,使用梯度下降进行优化,是几乎所有优化器的核心思想。当我们下山时,有两个方面是我们最关心的:
- 首先是优化方向,决定”前进的方向是否正确”,在优化器中反映为梯度或动量。
- 其次是步长,决定”每一步迈多远”,在优化器中反映为学习率。
所有优化器都在为在这两个方面做到最好而奋斗,希望大家牢记这两点,有助于更好的理解后面的内容。但同时也有一些其他问题,比如应该在哪里出发、路线错误如何处理……这是一些最新的优化器关注的方向。
2 传统的优化器们
SGD(Stochastic Gradient Descent)
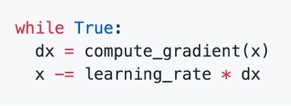
- 随机梯度下降的核心思想是,训练时,每次计算一批数据(batch)的误差,然后根据梯度信息对参数进行更新(迈出一步)。
- SGD的收敛效果稳定,但是存在一些问题:
SGD + Momentum
为了改善SGD更新时可能产生的震荡现象,受启发于物理学领域的研究,基于动量的随机梯度下降被提出了。

可以看到,相比SGD,基于动量的随机梯度下降使用一个速度vx和学习率相乘进行更新,而速度则为rho倍的上一时刻速度和这一时刻的梯度的和。这样参数更新就仿佛有了惯性,更新的方向不但和当前梯度有关,还和速度有关。而速度是由历史的梯度信息决定的,因此可以说是结合了更多的梯度信息做出了更加的决策。
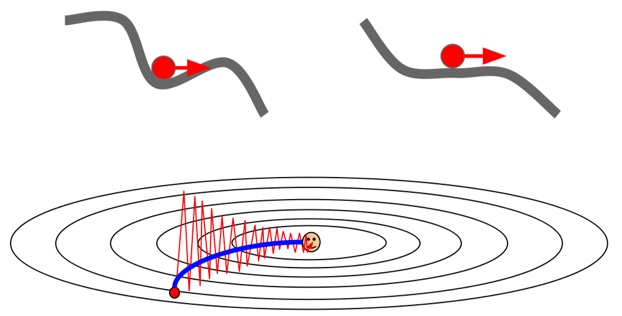
SGD + Momentum解决了前面经典SGD的两个问题。首先在局部最优点和鞍点,就算梯度为0,但是到了这里之后依然带有速度,所以可以继续更新。对于梯度沿不同方向差异大的问题也可以解决,因为动量的存在,不容易出现震荡的情形,路线更加平滑。
半程小结1
做一个小结,无论是经典SGD、还是 SGD+Momentum 都是为了使梯度更新的方向更加灵活,这对于优化神经网络这种非凸而且异常复杂函数空间的学习模型尤为重要。
然而,我们知道,稍小的学习率更加适合网络后期的优化,但前面的这些方法采用固定的学习率,并未将学习率的自适应性考虑进去。
简单的说,这两种方法关注了方向问题但没有关注步长问题。因此,为了解决步长的问题,让我们隆重介绍接下来的三个优化器!
AdaGrad

根据学习率自适应问题,AdaGrad优化器根据训练轮数的累加,对学习率进行了动态调整。
我们可以发现AdaGrad和SGD唯一的不同,就是多了一个分母,而这个分母就是梯度的累加平方和。因此,其学习率会基于每个维度的梯度的历史平方和进行缩放。随着训练逐渐进行,学习率会随着分母增大越来越小。因此,AdaGrad称作”自适应学习率”(Adaptive gradient algorithm)。
让我们来看看前面的那张损失函数梯度图。
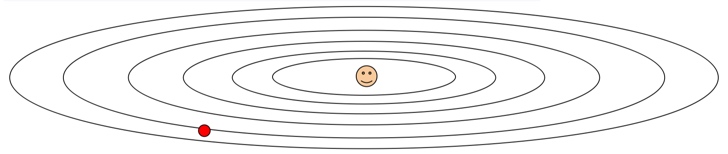
AdaGrad实现的效果,是对梯度较大的做较小的更新,对梯度较小的参数做较大的更新。对于上图,沿”陡峭”方向前进受阻; 沿”平缓”方向前进则加快。
但是,AdaGrad的这种自适应方法也带来了问题。如果梯度很大,导致分母积累非常快,一段时间后步长会收缩最终趋近于0,不再更新。因此,改进方案诞生了:
RMSProp

RMSProp 相比 Adagrad 的改进是,引入了一个衰减因子 decay_rate,这个衰减因子的值一般为0.9。也就是说,在进行梯度平方和累加时,从 Adagrad 的直接累加,变为了0.9倍的原来的平方和再加上0.1倍的当前梯度的平方。
这样就让梯度历史平方和也就是计算步长时的分母不会增长的太快,一定程度上解决了后期步长急剧下降问题。
Adam
RMSProp在学习率也就是步长控制上非常好,那现在我们要解决的只剩下方向问题了,因此今天的明星选手之一,Adam(almost)登场了。

Adam可以说是博采众长了,他在RMSProp的基础上又引入了之前SGD引入的动量思想,具体而言,它维护了两组值,也就是代码里的First Moment 和second Moment:
- First Moment就代表了方差的梯度的历史均值,控制了前进方向,和动量思想非常类似,使用beta1来模拟摩擦力,一般设为0.9
- Second Moment就代表了方差的梯度的方差,控制了学习率或者是前进步长,和RMSProp一样使用beta2来作为衰减因子,避免方差迅速累积,beta2一般设为0.99
听起来很完美了,但是我们观察这个计算过程,刚开始训练的时候会发生什么?由于first_moment、second_moment初始化为0,会导致训练初期阶段两值都偏向于0(因为beta1,beta2的取值)。因此,再引入一个偏差纠正,这样就构成了完全体Adam。

Adam既使用动量解决了方向的问题,也引入梯度的方差进行缩放实现了自适应步长。
传统优化器们的收敛效果对比
这个示例图对比了4种优化器的收敛过程(还是来自CS231n):
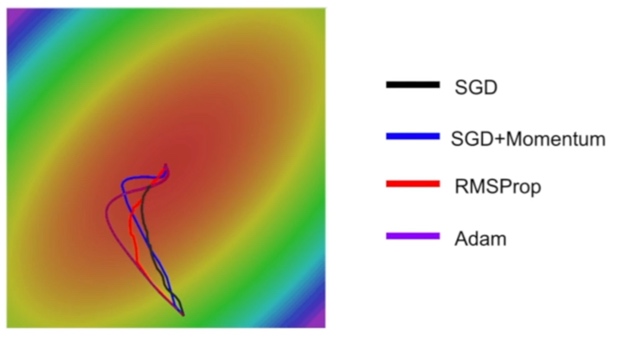
- 首先,通过 SGD+Momentum vs SGD、Adam vs RMSProp,这两组都是引入了动量,我们可以看到减少了震荡,路线更加平滑,这便是动量的作用。
- 而通过 自适应学习率的两种方法 vs SGD的两种方法,则可以发现自适应学习率可以更好地控制步长,在训练的后期更加谨慎,避免越过最优点。
3 新颖的优化器们
接下来介绍最新的几个优化器,这几个方法非常新,都是2019年7月之后提出的,所以主要会以论文为基础进行简介。
引子:Warm-up操作
包括 Adam,RMSProp 等在内的自适应学习率优化器都存在陷入局部最优的风险——初始学习率难以确定,较大的学习率可能导致模型训练不稳定。
为此,ResNet论文提出了一个对学习率的warm-up预热操作。它是什么呢?warm-up操作就是在刚开始训练的时候先使用一个较小的学习率,训练一些epoches,等模型稳定时再修改为预先设置的学习率进行训练。
warm-up非常有效,很快就变成了训练模型的一个必备trick。事实上,fastai 框架的模型训练函数 fit_one_cycle() 中就内置了 warm-up 操作。
RAdam
Warm-up大法确实好,但是很麻烦。有没有办法避免它呢?
2019年8月,来自UIUC的中国博士生Liyuan Liu提出了一种兼具Adam和SGD两者之美的新优化器——RAdam(paper),收敛速度快,还很鲁棒,一度登上了GitHub趋势榜。
他试图解决的问题是:自适应学习率优化器(如大名鼎鼎的Adam)需要warm-up操作,否则就会陷入糟糕的局部最优。但是warm-up操作针对不同数据集需要手动调整,非常麻烦。
作者首先研究了自适应学习率优化器需要warm-up操作,否则就会陷入糟糕的局部最佳的原因。通过实验发现,在没有warm-up的情况下,梯度的初始正态分布被迅速扭曲,这就相当于导致了一开始就陷入糟糕的局部最优状态。通过进一步研究,作者认为主要原因是因为在训练开始阶段优化器并没有看到足够的数据以至于不能做出准确的决策。而warm-up操作可以缓解这个问题,就是因为起到了一种减小方差的作用,更好的保持了参数的初始正态分布。
简单地说:Warm-up操作在最初的训练中起到了一种”减小方差”的作用。
因此,因此,RAdam使用了基于实际方差的整流函数进行”启发式warm-up”,直到数据的方差稳定下来。通过这样做,避免了需要手动warm-up,并且训练会自动稳定。一旦方差稳定下来,RAdam基本上在训练的剩余阶段就会退化成Adam甚至等同于SGD。下图是论文在ImageNet上训练ResNet-18的训练曲线。
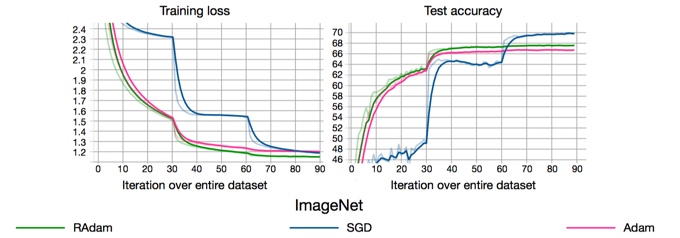
RAdam可以说是兼具了Adam和SGM两者之美。凭借优异的性能,RAdam在问世后基本成了优化器的最佳选择。
LookAhead
由 Geoffrey Hinton 大佬(提出反向传播那位)在2019年7月的《LookAhead optimizer: k steps forward, 1 step back》(Paper)论文中首次提出。文章内容比较注重算法,但其思想用白话来说就是:
- 假想你在一个山顶区域,你周围有很多条不同的路下山,有的也许可以让你轻松到达山下,有的路则会遇到险恶的悬崖和断层。
- 如果你孤身一人,去探索这些路就会有点麻烦,你得一条条尝试,假如选的路走不通,你很可能会卡在半路,回不到山顶、没办法试下一条路了。
- 但是如果你有个在山顶等你的好朋友,如果情况不太对就拉你回来,帮助你脱离险境的话,那么你被卡在半路的机会就小多了、找到合适的下山路的机会就大多了。
这就是LookAhead算法的思想。严格来讲,LookAhead不是一个优化器,而是一个可以配合各种优化器的优化方法。其核心思想是:维护两组权重,然后在它们之间进行插值——允许更快的也就是内部优化器的权重集 “向前看”或探索,而较慢的权重留在后面以提供更长期的稳定性。
具体实现是:每当内部优化器进行 5 或 6 轮探索。(通过 k 参数进行指定),Lookahead 就会在其保存的权重与 内部优化器 的最新权重之间进行差值相乘,并乘以 alpha 参数(默认情况下为0.5),同时更新内部优化器权重。
为什么能work呢,原文是这样解释的(我也看不懂):当 Lookahead 向高曲率方向振荡时,fast weights 更新在低曲率方向上快速前进,slow weights 则通过参数插值使振荡平滑。fast weights 和 slow weights 的结合改进了高曲率方向上的学习,降低了方差,并且使得 Lookahead 在实践中可以实现更快的收敛。
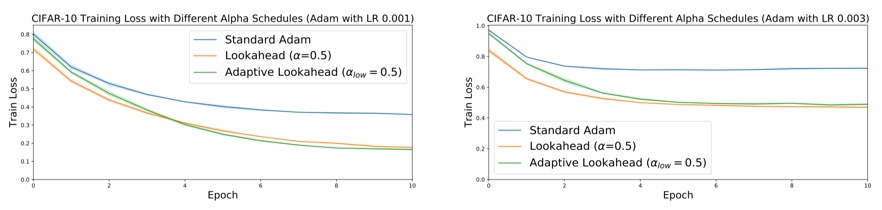
最后,文章在CIFAR-10数据集上进行了实验,可以观察到,LookAhead和Adam集成与单纯Adam的对比,可以看到尤其在训练后期,改进非常大。
半程小结2
RAdam的贡献是在训练开始时。利用动态整流器根据方差调整 Adam 的自适应动量,有效提供根据当前数据集启发式预热。是最好的优化器。、
LookAhead 的贡献则主要在训练中后期。需要和一个优化器结合使用(成为内部优化器),能够在整个训练期间提供健壮且稳定的优化效果。
那么,如果把两者结合,是否会起到更好的效果?
Ranger
一位名叫 Less Wright 的程序员就进行了这样的尝试,而且实现了很好的结果。因为只是整合了两个现有优化器,所以没有发paper,只是在Medium上发了一篇博客(地址)。
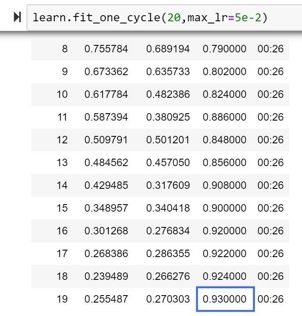
作者在ImageNette上训练了20个epoch,得到了比FastAI 排行榜记录高 1% 的准确率(第一名92%)。进一步测试表明,使用Ranger加上最新的Mish激活函数(而不是ReLU)可以产生更好的结果。
最后,作者表示,起Ranger这个名字,Ra为了致敬基本优化器RAdam,而LookAhead探索损失函数的地形,就像一个真正的游侠。(有趣的是,当我读到这篇时正沉迷云顶之弈,而且是忠实的游侠控,Glacial Rangers、Demon Rangers、Knight Rangers……
4 总结 - 该怎么选?
这篇文章介绍了这么多优化器,我到底应该在我的实验中选择哪一个呢?
- 在很多情况下,Adam 是一个很好的默认选择。因为使用固定的学习率,它也能正常工作。
- SGD+Momentum 的稳定性有时会比 Adam 好,但需要更多的对学习率进行微调。
- 建议一定试试Ranger。Ranger 是现在最先进的优化器(2019.8 提出),效果惊人,非常值得尝试。
参考
- Stanford CS231n Lecture03
- 其他论文链接已在文内指出
0 Preface
I haven't updated the blog in a while. This post is based on a group meeting presentation I gave in September 2019 — I thought it turned out reasonably well, so I'm sharing it here. Some of my interpretations may not be perfectly rigorous; corrections are welcome.
1 What Are We Optimizing?
The image that comes to mind first when I think about optimization is this classic “descending a mountain” diagram from Stanford CS231n:
Think of optimization as standing somewhere on a mountain (your current parameter values) and trying to find the best path down to the valley (the optimum). The most intuitive approach: look around, take one step in the steepest downhill direction, repeat — this is gradient descent. Your altitude is the loss function value; the step direction is the negative gradient (gradient points uphill, so its negation points downhill).
Two things matter most when descending:
- Direction — “Are we heading the right way?” This maps to gradient or momentum in optimizers.
- Step size — “How far do we go each step?” This maps to the learning rate.
Every optimizer is essentially trying to get these two things right. Keep this framing in mind — it makes everything else much clearer.
2 Classic Optimizers
SGD (Stochastic Gradient Descent)
SGD computes the loss over a mini-batch of data, then updates parameters by stepping in the negative gradient direction. Stable, but with two notable problems:
-
Local minima and saddle points: when the gradient is zero, the step size is also zero — training stalls.

-
Ill-conditioned loss landscapes: if the loss changes rapidly in one direction but slowly in another, the gradient is dominated by the steep dimension, causing oscillation in that direction while making slow progress along the flat one.
SGD + Momentum
Inspired by physics, momentum SGD introduces a velocity term:
Instead of updating purely based on the current gradient, parameters are updated using a velocity that accumulates over time — rho × previous_velocity + current_gradient. This creates inertia: the update direction depends on both the current gradient and the accumulated history.
This addresses both SGD problems: at saddle points, accumulated velocity carries the parameters through even when the gradient is zero; in ill-conditioned landscapes, momentum smooths out the oscillations.
Midpoint Summary 1
Both SGD and SGD+Momentum focus on improving direction. But they both use a fixed learning rate, which is a problem: a smaller learning rate is generally better in the later stages of training, but these methods don't adapt it.
Direction: ✓ Step size: ✗
Enter the adaptive learning rate optimizers.
AdaGrad
AdaGrad divides the learning rate by the running sum of squared gradients (per parameter). Parameters that received large gradients get smaller updates; parameters with small gradients get larger updates.
For the ill-conditioned landscape above, AdaGrad slows down updates in the steep direction and speeds them up in the flat one — much better convergence.
The downside: the denominator (sum of squared gradients) only grows over time. Eventually it becomes so large that the effective learning rate shrinks to near zero, and training stops making progress.
RMSProp
RMSProp fixes AdaGrad's decay problem by using an exponential moving average of squared gradients instead of a cumulative sum. A decay_rate (typically 0.9) controls how quickly old gradients are forgotten:
new_sq_sum = 0.9 × old_sq_sum + 0.1 × current_gradient²
This prevents the denominator from growing unboundedly, keeping the effective learning rate healthy throughout training.
Adam
RMSProp solves the step size problem. What about direction? Adam combines RMSProp's adaptive step sizes with SGD's momentum:
Adam maintains two running estimates:
- First moment (mean of gradients) — controls direction, like momentum. Controlled by
beta1 (typically 0.9).
- Second moment (variance of gradients) — controls step size, like RMSProp. Controlled by
beta2 (typically 0.99).
One catch: both moments are initialized to zero, so early in training they're biased toward zero. Adam corrects for this with bias correction terms — giving us the full Adam optimizer:
Adam handles both direction and step size adaptively.
Comparing Classic Optimizers
Two observations from this convergence comparison:
- Momentum helps: SGD+Momentum vs SGD, and Adam vs RMSProp — adding momentum reduces oscillations and smooths the path.
- Adaptive learning rates help: adaptive methods (AdaGrad family) are more careful late in training, avoiding overshooting the optimum.
3 Modern Optimizers
These are all from mid-2019, so they're covered at the paper level rather than in deep implementation detail.
Preamble: Learning Rate Warm-up
Adaptive learning rate optimizers (Adam, RMSProp, etc.) are sensitive to the initial learning rate — too high and training is unstable. The ResNet paper introduced warm-up: start with a very small learning rate for a few epochs, then ramp up to the target rate once the model stabilizes.
Warm-up works well enough that it became standard practice. It's even built into fastai's fit_one_cycle().
RAdam
Great technique, painful to tune. Can we avoid it?
In August 2019, Liyuan Liu (UIUC) proposed RAdam (paper) — an optimizer that combines the strengths of Adam and SGD with automatic, data-driven warm-up. It hit the GitHub trending list quickly.
The core insight: without warm-up, the initial gradient distribution gets distorted rapidly, pushing the optimizer into poor local minima early on. This happens because there isn't enough data yet for the adaptive estimates to be accurate. Warm-up works because it acts as a variance reduction mechanism, preserving the initial gradient distribution.
RAdam formalizes this with a rectifier based on the actual variance of the adaptive learning rate. Training automatically stabilizes without manual warm-up tuning. Once the variance stabilizes, RAdam essentially degrades to Adam (or even SGD).
RAdam became the go-to optimizer choice after its release.
LookAhead
Proposed by Geoffrey Hinton (yes, the backprop guy) in July 2019: LookAhead Optimizer: k Steps Forward, 1 Step Back (paper).
The intuition: imagine you're at a mountain summit with many possible paths down. Some lead safely to the valley; others end in cliffs. Exploring alone is risky — you might get stuck partway and can't backtrack. But if a friend waits at the top and pulls you back when things go wrong, you can explore much more safely.
LookAhead isn't a standalone optimizer — it's a wrapper around any inner optimizer. It maintains two sets of weights:
- Fast weights (inner optimizer): actively explores the loss landscape.
- Slow weights: stay behind, providing long-term stability.
Every k steps (default: 5-6), LookAhead interpolates the slow weights toward the fast weights by a factor alpha (default: 0.5), then resets the fast weights to this interpolated position. This damping effect smooths oscillations in high-curvature directions while maintaining fast progress in low-curvature ones.
On CIFAR-10, LookAhead+Adam showed significant improvements over plain Adam, especially in the later stages of training.
Midpoint Summary 2
- RAdam — helps most at the start of training. Automatically provides warm-up by adjusting Adam's adaptive momentum based on gradient variance.
- LookAhead — helps most in the middle and late stages. Wraps any inner optimizer and provides robust, stable optimization throughout training.
What if we combine them?
Ranger
Programmer Less Wright did exactly this, and wrote about the results in a Medium post. No paper — just an implementation combining RAdam and LookAhead.
Training ResNet on ImageNette for 20 epochs, Ranger exceeded the FastAI leaderboard's top score by 1% (beating first place at 92%). Further experiments showed even better results when pairing Ranger with the Mish activation function instead of ReLU.
The name: “Ra” honors RAdam; “LookAhead” explores the loss landscape like a ranger scouting terrain. (Interestingly, I was deep into TFT when I read this, firmly in the Rangers-comp camp — Glacial Rangers, Demon Rangers, Knight Rangers…)
4 Summary — Which One Should You Use?
- Adam is a solid default in most cases. Works well even with a fixed learning rate.
- SGD+Momentum can be more stable than Adam, but requires more careful learning rate tuning.
- Try Ranger. It was state-of-the-art when this was written (2019.8) and produces impressive results. Worth trying on any new project.
References
- Stanford CS231n Lecture 3
- Paper links are included inline throughout the post